-
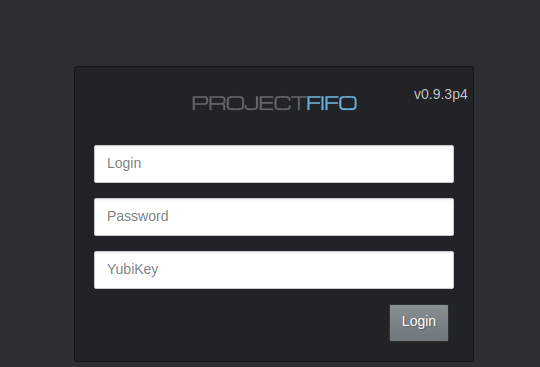
Change theme for project-fifo Web UI
Exploring more of Project-Fifo, I happened upon this gem. You can change the web UI theme! Log into your fifo server and edit /opt/local/fifo-cerberus/config/config.js then simply set the theme to dark. Clear your browser cache and reload the WebUI. Here’s what it will look like. If you want to customize the theme further, you can…
-
Setup Package Cache Server on Ubuntu 18.04
If you’re like me and have several Debian/Ubuntu machines on your network there’s going to come a time when you need to upgrade them. Doing so, will use up a lot of bandwidth while every machine will likely be downloading the same packages. This may or may not upset your significant other who’s binge-watching Gilmore…
-
The home lab
After reading about others home lab environments, I was inspired to write about mine. It’s nothing too fancy but maybe somebody out there will find it interesting. I’ve flipped-flopped several times between various operating systems and hypervisors trying to find the solution that best fits my needs. I’ve tried everything from pure Debian (kvm/libvirt, lxc),…
-
Nginx and Letsencrypt on SmartOS
acme_tiny is a nice, small utility for creating and renewing your doman SSL/TLS certificates. It’s less than 200 lines of bash and just works. Here’s how to set it up and have your certificate automatically renewed once a month. First, let’s get things installed; nginx and the acme-tiny client and setup the necessary directories. Add…
-
Install elasticsearch 5.x on SmartOS
Whenever possible, I like running software in containers instead of kvms. Aside from the obvious performance gains, server density increases significantly since you’re not kidnapping huge chunks of DRAM from the OS and holding it hostage. I recently had a need to setup an elasticsearch 5.x cluster on a SmartOS machine. It was mostly straight-forward…
-
Bhyve pfSense 2.4 no console menu
I ran into an annoying issue today while trying to install pfsense 2.4.2 in a bhyve VM using the ISO installer. Everything went swimmingly until post-install when pfsense finished startup and never provided the expected pfSense console. All it would show is bootup complete. I went through and confirmed /etc/ttys was configured properly and added…